Best Practices in Backup Systems: the 3-2-1 Rule
The 3-2-1 Rule is a common guideline for ensuring resilience in backup systems — that is, the ability to recover from partial failures without losing data. https://www.veeam.com/blog/321-backup-rule.html
To summarize:
- Keep at least 3 copies of your data. If 1-2 of them are compromised, you still have another to restore from.
- Use 2 different media types (local storage, cloud, disk, tape, etc). Different media types have different failure modes, so using more than one reduces the chance of simultaneous loss.
- At least 1 backup should be offsite. Aim for geographic and network separation to prevent a single disaster from compromising all of your backups. Utilize cloud storage or replicate your backups to another server that you keep at a friend or relative’s house, for example.
Currently, much of my data lives solely on my laptop’s internal SSD… not ideal. Time to fix that.
In my homelab server, my only storage is the 2TB SSD, which doesn’t provide any redundancy to prevent data loss in the event of a system/drive failure or a disaster like my house burning down…
What I’m Doing
I decided on backing up to an external HDD to keep as an on-prem, offline backup as well as automating encrypted cloud backups to Backblaze B2.
I already have a 2TB external HDD and 500GB external SSD that I could use for my offline backup, although I know USB isn’t ideal either. Additional drives attached via SATA would offer better reliability and performance… I will figure this part out later.

What I Could Do Instead
Here are a few other options I considered. Ultimately, I want to keep a small footprint and minimize costs. After all, this is for personal use and experimentation — I don’t need 5 9’s of uptime to appease my stakeholders!
- Buy or build a NAS, configured with RAID for improving redundancy and performance
- Obtaining a NAS:
- Synology has a strong reputation for quality and ease of use, but I’m wary of their vendor lock-in — they restrict certain third-party HDDs, which could limit future upgrades or repairs.
- Ugreen
- Build your own by adding multiple HDDs to a second-hand workstation or even a raspberry pi. Then install TrueNAS
- Obtaining a NAS:
- Buy an Uninterruptible Power Supply (UPS) for power resiliency
- This is meant to keep the on-prem server/NAS running temporarily in the event of a power outage, at least giving enough time for it to shut down gracefully. For critical systems, use a UPS in conjunction with a generator for better redundancy in extended outages.
- Install a NAS at a friend or relative’s house for off-site backups
- Use Tailscale for secure remote access
- Encrypt data in transit and at rest — even if you trust your friend, you can’t guarantee their home’s network and physical security from threats like ransomware and physical intruders.
- Use smart PDU, or configure WoL to only power on the system when needed for pushing backups. This system helps to reduce wasted electricity for your hosting party, but it also reduces risk of getting ransomwared if their network is compromised, since this also functions as an offline backup.
- Store a standalone, offline disk off-site, again, potentially at a friend or relative’s house
- Encrypt your backup data as you won’t be able to ensure its physical security once it leaves your possession
- Store in a safe-deposit box at a post office or bank
- For a stealthier approach, store your backup on a microSD card which is easier to conceal… even put it in a hollow nickel if you want.
- AWS Deep Glacier for cloud backups
- Deep Glacier is supposed to be even cheaper than Backblaze B2 for data archival, at just $1/TB/Month; anecdotally I’ve read that these savings come at the cost of a painful restore process with slow data retrieval and a more complicated fee structure than backblaze. Since my on-prem backups aren’t as robust and it’s definitely possible that I’ll need to restore from cloud at some point, Backblaze makes more sense to me for now.
- Use Veame to backup to S3-compatible storage like AWS Glacier or Backblaze B2
- Requires license, not available with the community edition.
- https://www.backblaze.com/blog/how-to-back-up-veeam-to-the-cloud/
Implementation (WIP)
Discover where my virtual disks are, from the host:
qm config <VMID>
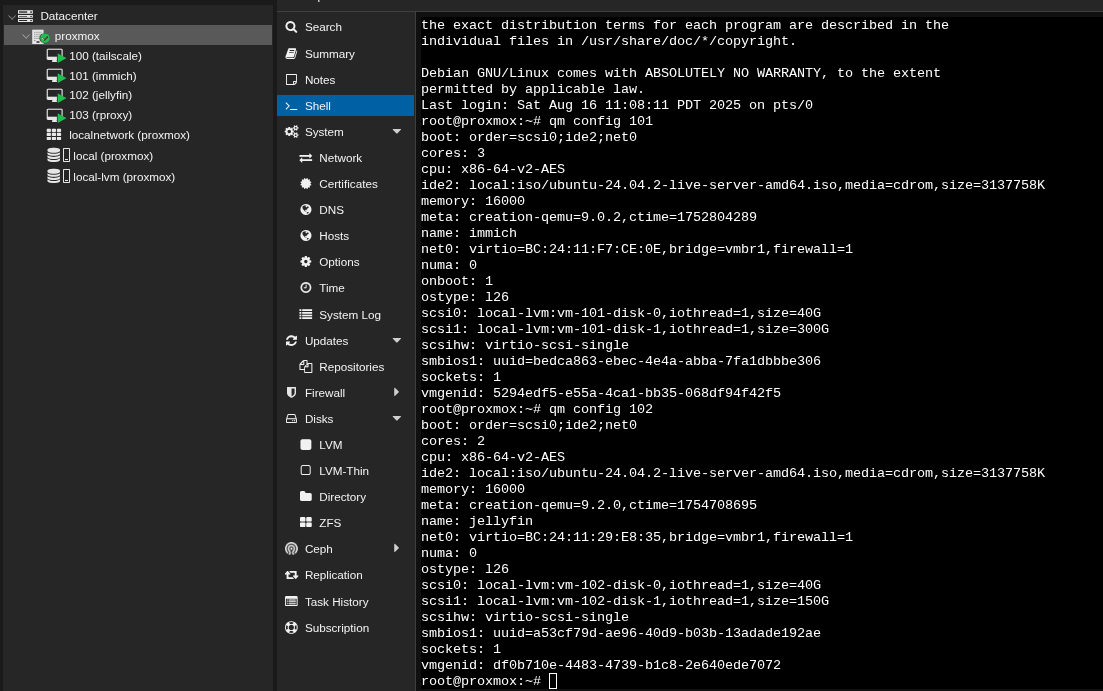
We have:
- vm-101-disk-1
- vm-102-disk-1
We can also list all logical volumes with lvs:
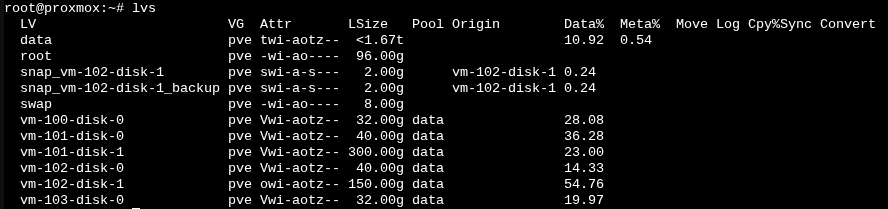
I realized that if I backup these volumes entirely as disk images, I’ll also be wasting storage by backing up the empty space in the volumes. I want to have a centralized, single backup job from the proxmox host, without wasting space. In other words, I want to do a filesystem backup rather than backing up the raw disk images.
Make a bucket, application key for read/write access, and append the following into /root/.bashrc, filling in your information:
export B2_REPO_BASE="..."
export B2_ACCOUNT_ID="..."
export B2_ACCOUNT_KEY="..."
export RESTIC_PASSWORD="..."
Run source /root/.bashrc to reload the environment.
Initialize bucket with folders:
restic init --repo b2:your-bucket-name:immich
restic init --repo b2:your-bucket-name:jellyfin
Confirm these commands run succesffully and the folders are initialized in Backblaze B2:
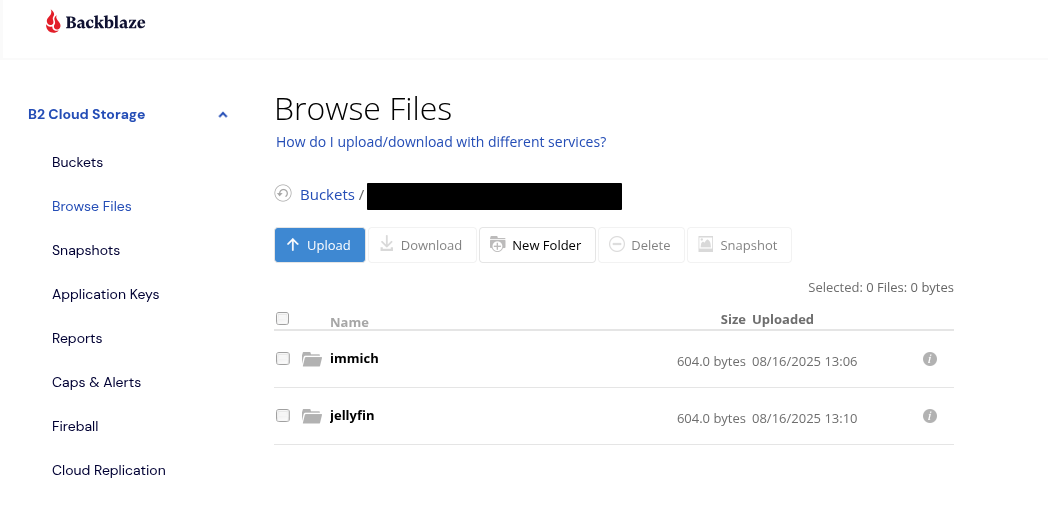
We’ll reference these environment variables in the backup script.
/root/backup.sh
#!/bin/bash
set -euo pipefail
# Where backups go
IMMICH_REPO="b2:${B2_REPO_BASE}:immich"
JELLYFIN_REPO="b2:${B2_REPO_BASE}:jellyfin"
# VM IDs
IMMICH_VM=101
JELLYFIN_VM=102
# Logging
LOGFILE="/var/log/proxmox-backup.log"
exec > >(tee -a "$LOGFILE") 2>&1
timestamp() {
date +"[%Y-%m-%d %H:%M:%S]"
}
backup_vm_disk() {
local VMID=$1
local DISK=$2
local REPO=$3
echo "$(timestamp) Stopping VM $VMID..."
qm stop "$VMID"
SNAP_NAME="backup-$(date +%s)"
DISK_PATH=$(qm config "$VMID" | awk -v disk="$DISK" '$1 == disk {print $2}' | cut -d',' -f1)
echo "$(timestamp) Creating LVM snapshot..."
lvcreate --size 5G --snapshot --name "${SNAP_NAME}" "$DISK_PATH"
SNAP_PATH="/dev/$(dirname "$DISK_PATH")/${SNAP_NAME}"
echo "$(timestamp) Mounting snapshot..."
mkdir -p /mnt/backup
mount "$SNAP_PATH" /mnt/backup
echo "$(timestamp) Running restic backup to $REPO..."
restic -r "$REPO" backup /mnt/backup
echo "$(timestamp) Cleaning up..."
umount /mnt/backup
lvremove -f "$SNAP_PATH"
echo "$(timestamp) Restarting VM $VMID..."
qm start "$VMID"
echo "$(timestamp) Finished backup for VM $VMID"
}
echo "$(timestamp) Starting backups..."
backup_vm_disk $IMMICH_VM vm-101-disk-1 $IMMICH_REPO
backup_vm_disk $JELLYFIN_VM vm-102-disk-1 $JELLYFIN_REPO
echo "$(timestamp) Running forget/prune..."
restic -r "$IMMICH_REPO" forget --keep-last 3 --prune
restic -r "$JELLYFIN_REPO" forget --keep-last 3 --prune
echo "$(timestamp) Backups complete."